
Tired of slow, unreliable ad-hoc SQL queries? This article shows you how to build a scalable, maintainable ETL pipeline using dbt and cloud infrastructure. We'll transform your messy data processes into efficient, automated workflows. Learn how to leverage dbt's power for data transformation, testing, and collaboration, all while enjoying the scalability and reliability of the cloud. Get ready to revolutionize your data workflows!
Istruzioni Passo dopo Passo
-
Fase 1: Inizio con un approccio Ad Hoc
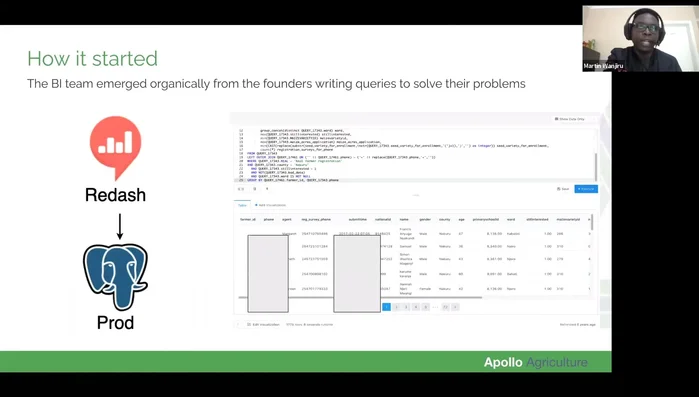
- utilizzo iniziale di Redash per la creazione di dashboard basati su query SQL direttamente sul database di produzione.

Fase 1: Inizio con un approccio Ad Hoc -
Fase 2: Ottimizzazione delle prestazioni
- Migrazione da query sul database di produzione a una replica per migliorare le prestazioni.
Fase 2: Ottimizzazione delle prestazioni -
Fase 3: Identificazione dei colli di bottiglia
- crescita esponenziale dei dati e complessità delle query SQL (oltre 300.000 righe), rendendo il processo di debugging e manutenzione molto difficile.
Fase 3: Identificazione dei colli di bottiglia -
Fase 4: Scelta della soluzione ETL scalabile
- selezione di Postgres come data warehouse (per la gestione di dati GIS), Stitch Data per la replica dei dati, GitLab CI per la gestione dei workflow e dbt per la trasformazione dei dati e la creazione di modelli.
Fase 4: Scelta della soluzione ETL scalabile -
Fase 5: Implementazione di dbt per la trasformazione dei dati
- creazione di modelli dbt (istruzioni SQL) per gestire la logica di business ripetitiva, migliorando la leggibilità, la manutenibilità e la testabilità del codice.
Fase 5: Implementazione di dbt per la trasformazione dei dati -
Fase 6: Garanzia di qualità e collaborazione
- utilizzo dei test integrati di dbt per garantire l'accuratezza dei dati e la documentazione generata automaticamente per facilitare la collaborazione e l'onboarding.
Fase 6: Garanzia di qualità e collaborazione -
Fase 7: Architettura ETL definitiva
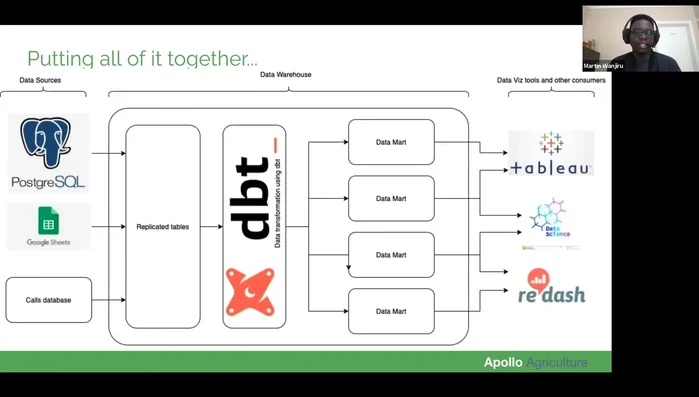
- le sorgenti dati vengono replicate nel data warehouse tramite Stitch. dbt trasforma i dati creando modelli testati e documentati. Gli strumenti di visualizzazione accedono direttamente al data warehouse.
Fase 7: Architettura ETL definitiva





Tips
- Pianificazione accurata: dedicare tempo alla scelta degli strumenti e all'architettura del data warehouse, considerando le esigenze presenti e future.
- Utilizzo di macro e funzioni personalizzate: automatizzare processi ripetitivi tramite macro dbt per migliorare l'efficienza e la manutenibilità del codice.
- Testing robusto: implementare un sistema di test completo per garantire l'accuratezza e la coerenza dei dati.
Common Mistakes to Avoid
1. Mancanza di test adeguati
Motivo: La mancanza di test unitari e di integrazione nei modelli dbt può portare a errori subdoli e difficili da individuare in produzione, compromettendo la qualità dei dati e l'affidabilità del processo ETL.
Soluzione: Implementare una suite completa di test dbt, inclusi test di dati, test di schema e test di conformità, per garantire l'accuratezza e la coerenza dei dati.
2. Gestione inefficiente delle dipendenze
Motivo: Dipendenze mal gestite tra i modelli dbt possono causare problemi di ordine di esecuzione, errori a cascata e tempi di elaborazione eccessivi, rallentando l'intero processo ETL e rendendolo meno scalabile.
Soluzione: Definire chiaramente le dipendenze tra i modelli dbt utilizzando la funzionalità `depends_on` e ottimizzare l'ordine di esecuzione per evitare colli di bottiglia.
FAQs
Quali sono i principali vantaggi di utilizzare dbt per la creazione di pipeline ETL rispetto all'utilizzo di solo SQL ad-hoc?
dbt offre numerosi vantaggi: maggiore organizzazione e manutenibilità del codice grazie alla modularità; possibilità di versionare e testare il codice; automazione dei processi ETL; scalabilità grazie all'integrazione con servizi cloud; e miglior collaborazione tra team grazie alle funzionalità di revisione del codice.