
Tired of manually typing text from photos of books and documents? PDF Element offers a seamless solution! This complete guide shows you how to effortlessly extract text from images using PDF Element's powerful OCR capabilities. Learn step-by-step how to improve accuracy, handle various document types, and save valuable time. Discover the efficiency of PDF Element for all your text extraction needs.
Istruzioni Passo dopo Passo
-
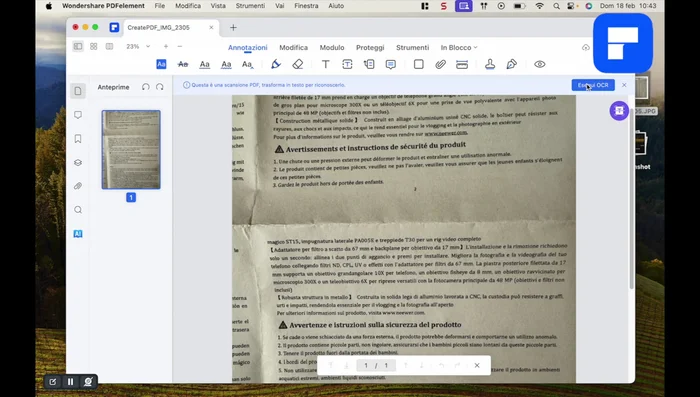
Preparazione dell'immagine
- Fotografare il documento con lo smartphone.

Preparazione dell'immagine -
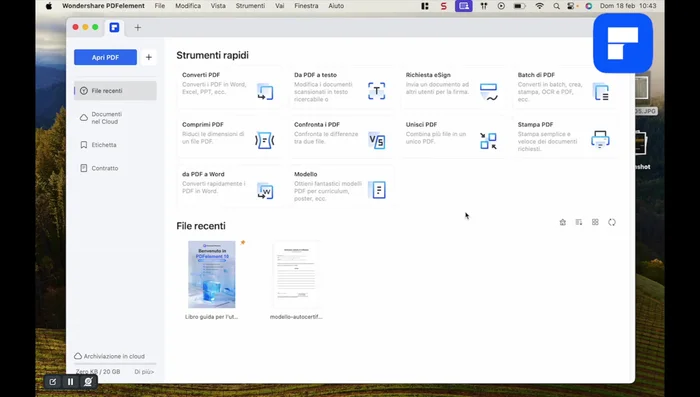
Importazione in PDF Element
- Aprire PDF Element e selezionare 'Nuovo PDF da immagini'.
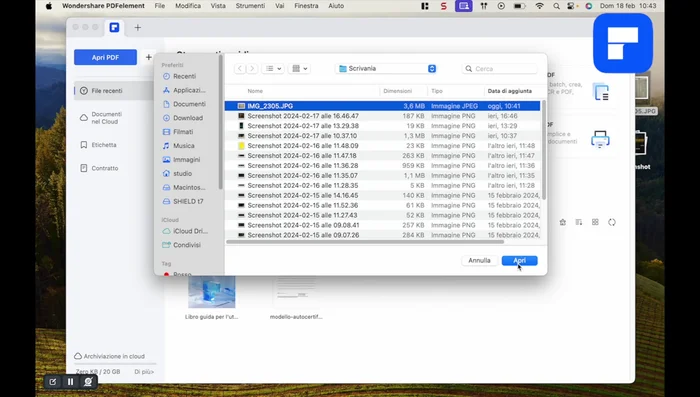
- Importare la fotografia del documento.
Importazione in PDF Element -
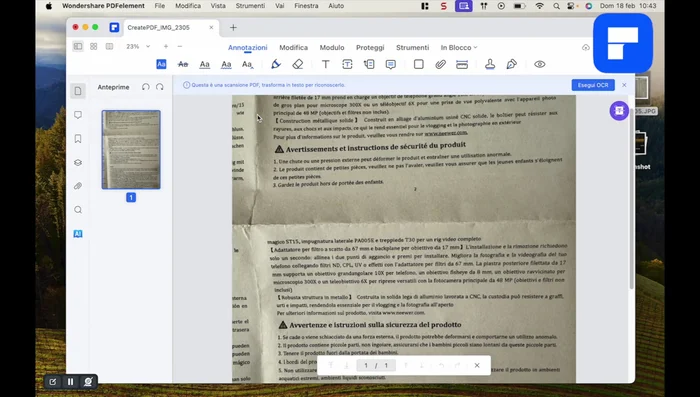
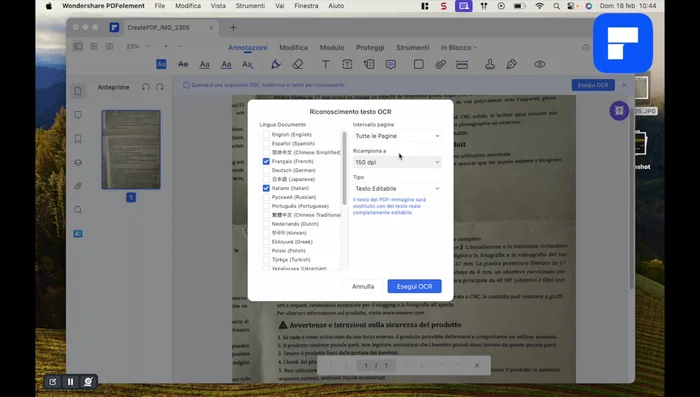
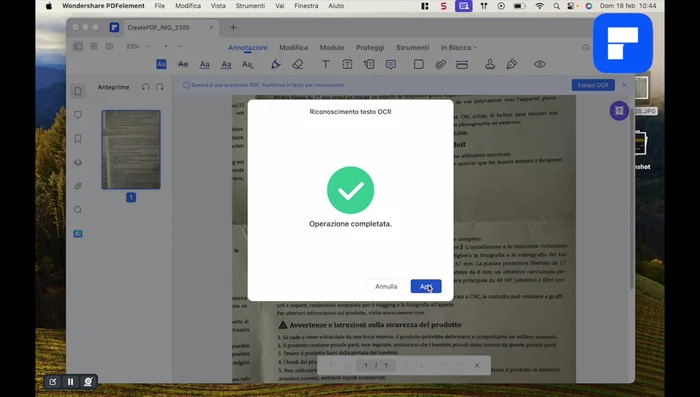
Esecuzione dell'OCR
- Ruotare la pagina se necessario.
- Selezionare 'Esegui OCR' e scegliere la lingua (italiano o altre lingue, se necessario).
- Scegliere le opzioni di OCR (intervallo di pagine, risoluzione, testo editabile o immagine con testo ricercabile). Si consiglia 'testo editabile'.
Esecuzione dell'OCR -
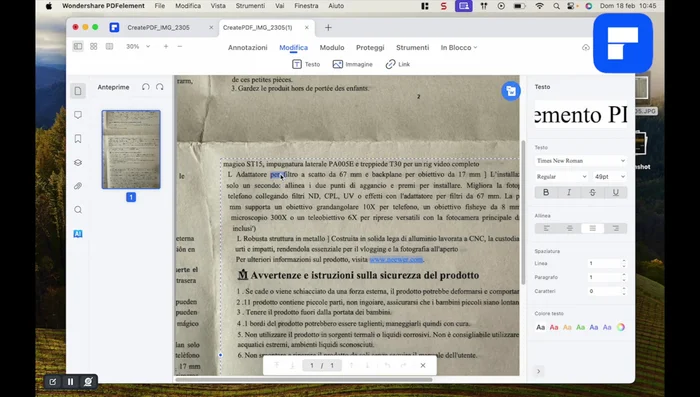
Apertura e Revisione del Documento
- Cliccare su 'Apri'.
- Modificare il testo (se necessario) usando la funzione di modifica.
Apertura e Revisione del Documento -
Salvataggio del PDF
- Salvare il documento come PDF.
Salvataggio del PDF
Tips
- Fotografare il documento con buona luminosità e in buone condizioni per ridurre gli errori di OCR.
- Utilizzare PDF Element, un software professionale con OCR integrato, per risultati ottimali.
Common Mistakes to Avoid
1. Immagini di bassa qualità
Motivo: Foto sfocate, poco illuminate o con ombre intense rendono difficile la lettura del testo da parte di PDF Element, portando a risultati imprecisi o incompleti.
Soluzione: Assicurarsi di utilizzare immagini nitide, ben illuminate e con un contrasto adeguato.
2. Angolo di ripresa errato
Motivo: Se la foto è scattata da un'angolazione troppo inclinata, il testo risulterà distorto e difficile da riconoscere per il software.
Soluzione: Scattare le foto in modo che il libro o il documento siano perpendicolari alla fotocamera.
3. Testo troppo piccolo o troppo denso
Motivo: Caratteri minuscoli o un testo troppo compresso possono rendere difficile l'estrazione accurata del testo.
Soluzione: Preferire immagini di testo più grande e con spaziatura adeguata tra le righe.